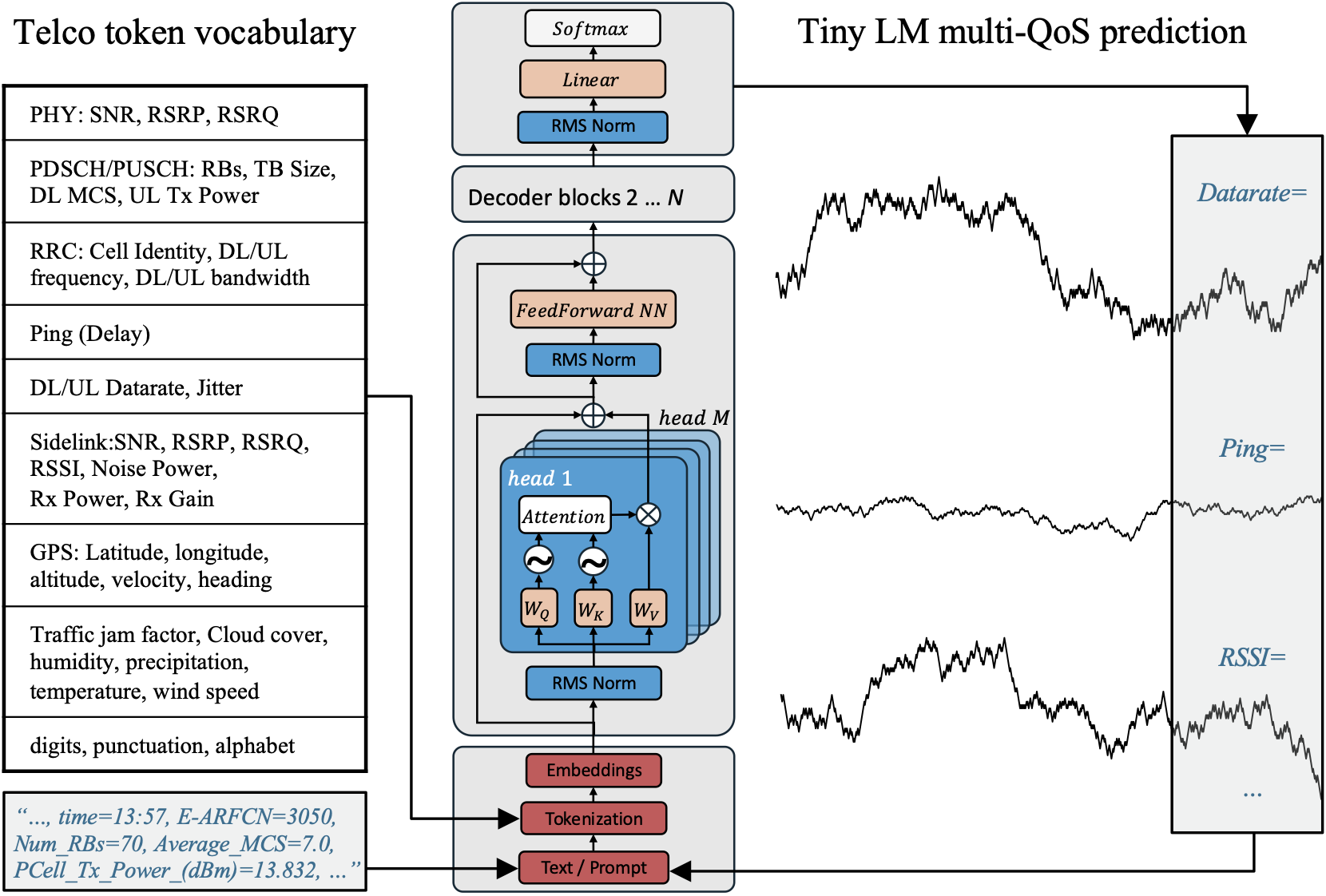
My current research interests lie in the domain of neural codecs like language
model-based general-purpose compressors. I am also working on methods specifically tailored to
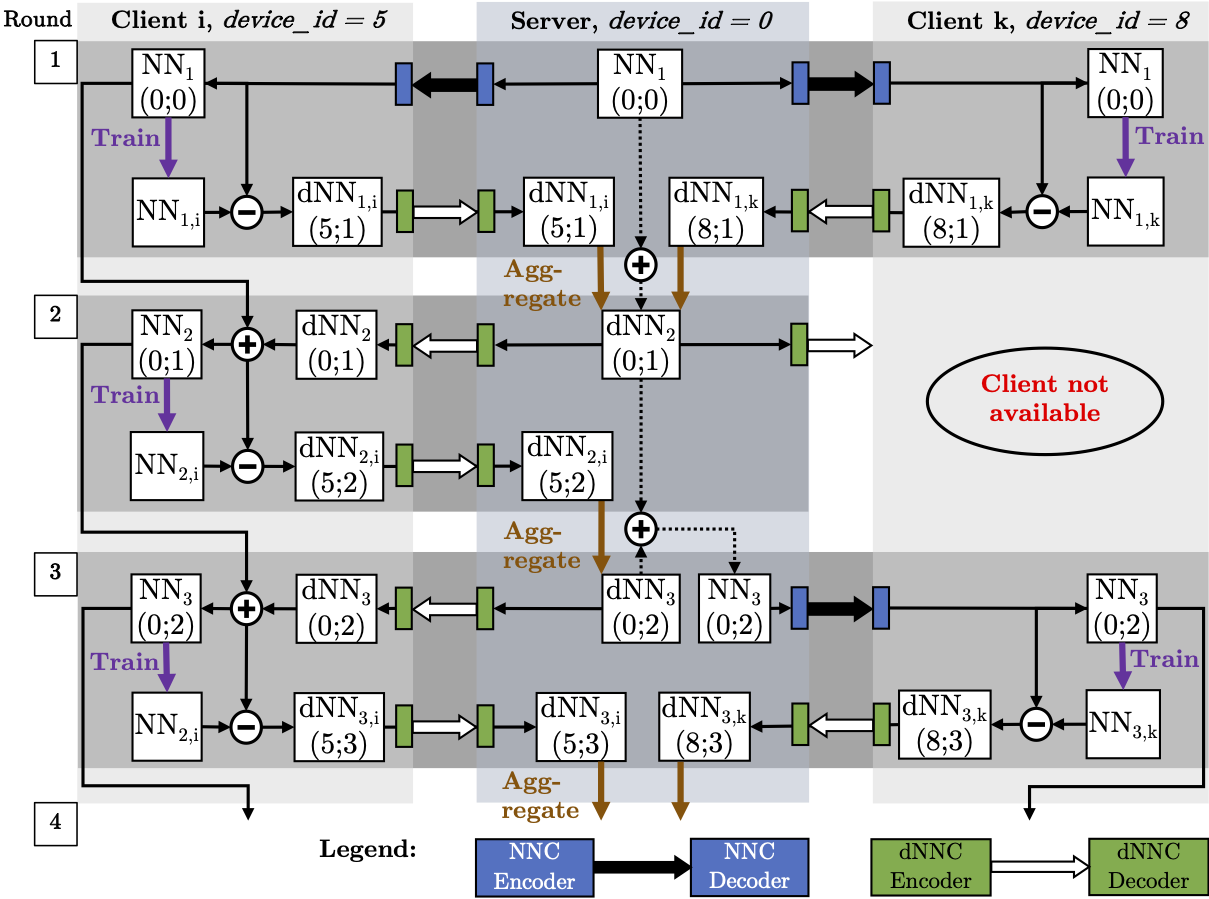
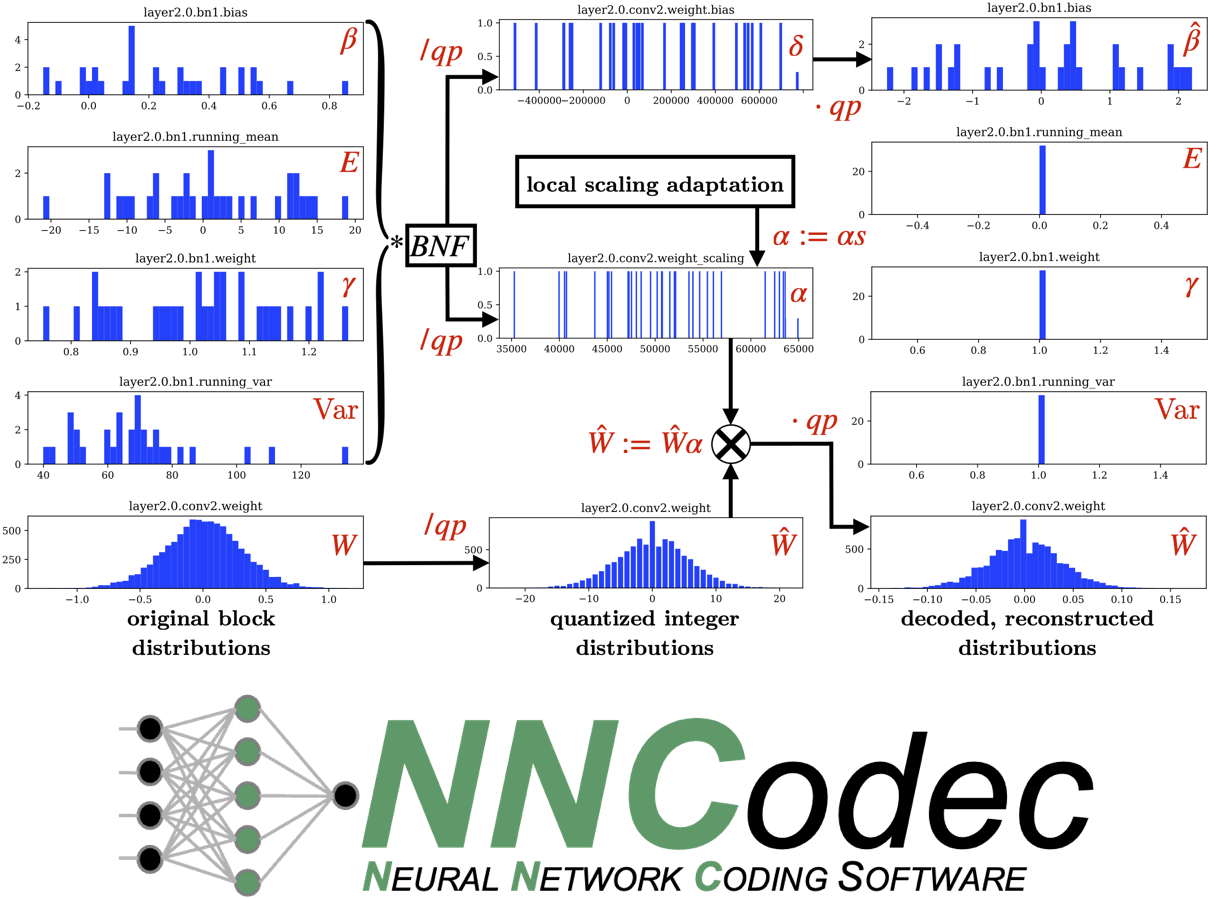
compression of neural networks and the efficient transmission of
incremental neural data, e.g., within distributed learning scenarios like federated
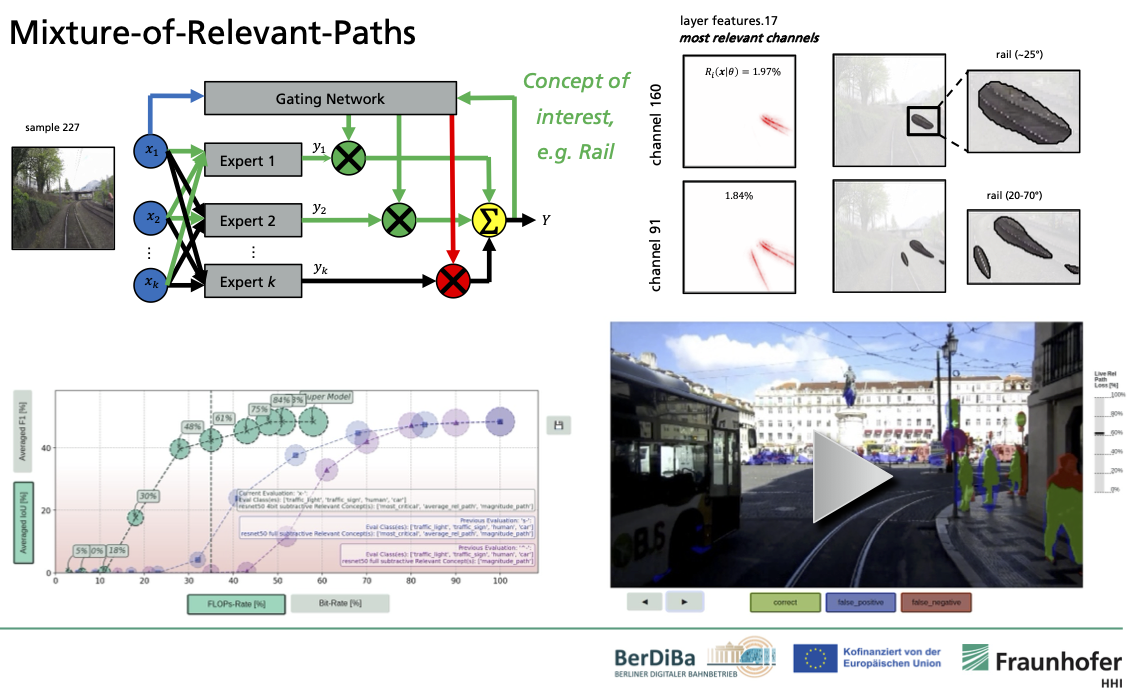
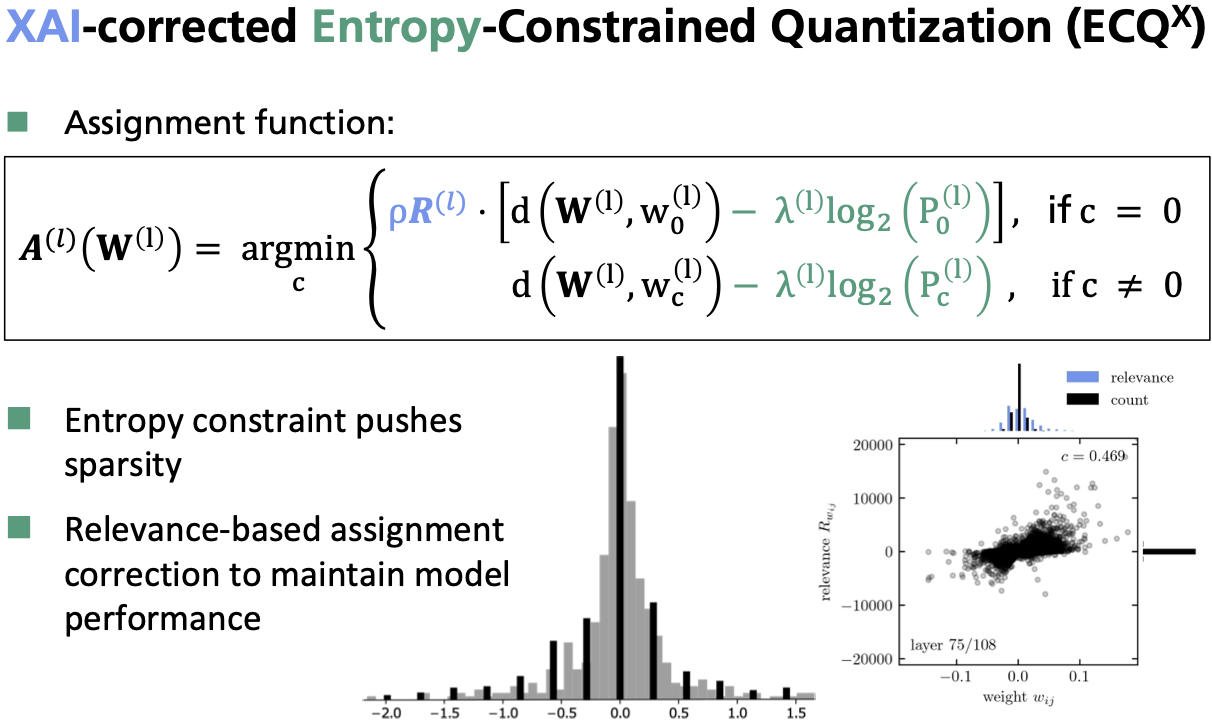
or split learning. My methods leverage explainable AI (XAI) techniques and concepts
of information theory.
As a regular attendee of Moving Picture Experts Group (MPEG) meetings since 2020, I have contributed several compression tools and syntax to the
first and second editions of the ISO/IEC 15938-17
standard for
Neural Network Coding (NNC).
I completed my M.Sc. in Biomedical Engineering in 2020, under the guidance of Klaus-Robert Müller at
the Technical University of Berlin.
Before joining Fraunhofer HHI, and during my bachelor's studies in Microsystems Engineering, I was part
of the Sensor Nodes & Embedded Microsystems group at Fraunhofer IZM, which was invaluable
while working on the FantastIC4 low-power NN accelerator.